In this Part 1 project, I’ll walk through creating a python script to extract random jokes from the Official Random Joke API. Click here for Part 2.
https://official-joke-api.appspot.com/random_joke
Clicking on the link above will give you data on a random joke.
Here’s what we’ll do in this project (feel free to follow along with your own favorite IDE):
- Get a random joke from the API
- Parse it out into a pandas DataFrame
- Authenticate and connect to a BigQuery database
- Load the random joke data into a BigQuery table
- Deploy the script via crontab to run every minute, thus getting a new joke into our database every 60 seconds
- Tear down (remove crontab lines)
Let’s dive in…
Setup
First off, fire up your favorite IDE… (mine is Visual Studio Code). Add a new project folder and add 2 files:
- main.py
- README.md
At this step, activate your virtual environment… For me, I have a virtual environment called “vscode-env” setup with Conda. So I run the following command in the terminal:
conda activate vscode-envMake the First API Request
Next I know I’m going to be working with the requests library, so I’ll import that and pull my first joke…
import requests
url = 'https://official-joke-api.appspot.com/random_joke'
joke_data = requests.get(url).text
print(joke_data)The following is what the script returns in the terminal (yours may be different since it’s random).
{"type":"general","setup":"I can't tell if i like this blender...","punchline":"It keeps giving me mixed results.","id":70}Loading the Data into a Dictionary
Now I see that it looks in the form of a dictionary… however if I run print(type(joke_data)), it returns:
<class 'str'>So the data type is actually of a type string.
We’ll need to turn this into a type of dictionary. (In order to make it easier for us to parse out and extract the data and turn it into a DataFrame.)
To turn a string type into a dict type, we’ll adjust our code to add in the json library, and use the function json.loads().
Quick tip: I didn’t know this at first and it confused me, but I thought it was json “loads”… like one word. And there is also another json function called json.load(). Which confused me… I thought “What is the difference between json.load() and json.loads()?” Then I realized the “loads” is actually “load” + “s”. The “s” is for string. –> You are loading the json from a string 😱.
The following is our code adjustment:
import requests
import json ###Added
url = 'https://official-joke-api.appspot.com/random_joke'
joke_data = requests.get(url).text
joke_dict = json.loads(joke_data) ###Added
print(type(joke_dict))
print(joke_dict)<class 'dict'>
{'type': 'general', 'setup': 'What is the hardest part about sky diving?', 'punchline': 'The ground.', 'id': 250}Yay!
Now we have a dictionary data type assigned to the variable: joke_dict.
We can proceed now to parsing it out and turning it into a DataFrame…
Note: there are different ways of going about this, but the following is what I found works…
Parsing Out the Data
First, we’ll assign each value to a variable:
joke_id = joke_dict['id']
joke_type = joke_dict['type']
joke_setup = joke_dict['setup']
joke_punchline = joke_dict['punchline']I also wanted to get some practice loading data into a partitioned table, so I added another variable here to represent a fifth column: datetime_extracted.
from datetime import datetime as dt ###Added
joke_id = joke_dict['id']
joke_type = joke_dict['type']
joke_setup = joke_dict['setup']
joke_punchline = joke_dict['punchline']
joke_datetime_extracted = dt.now() ###AddedNext, I create an empty DataFrame while naming the columns:
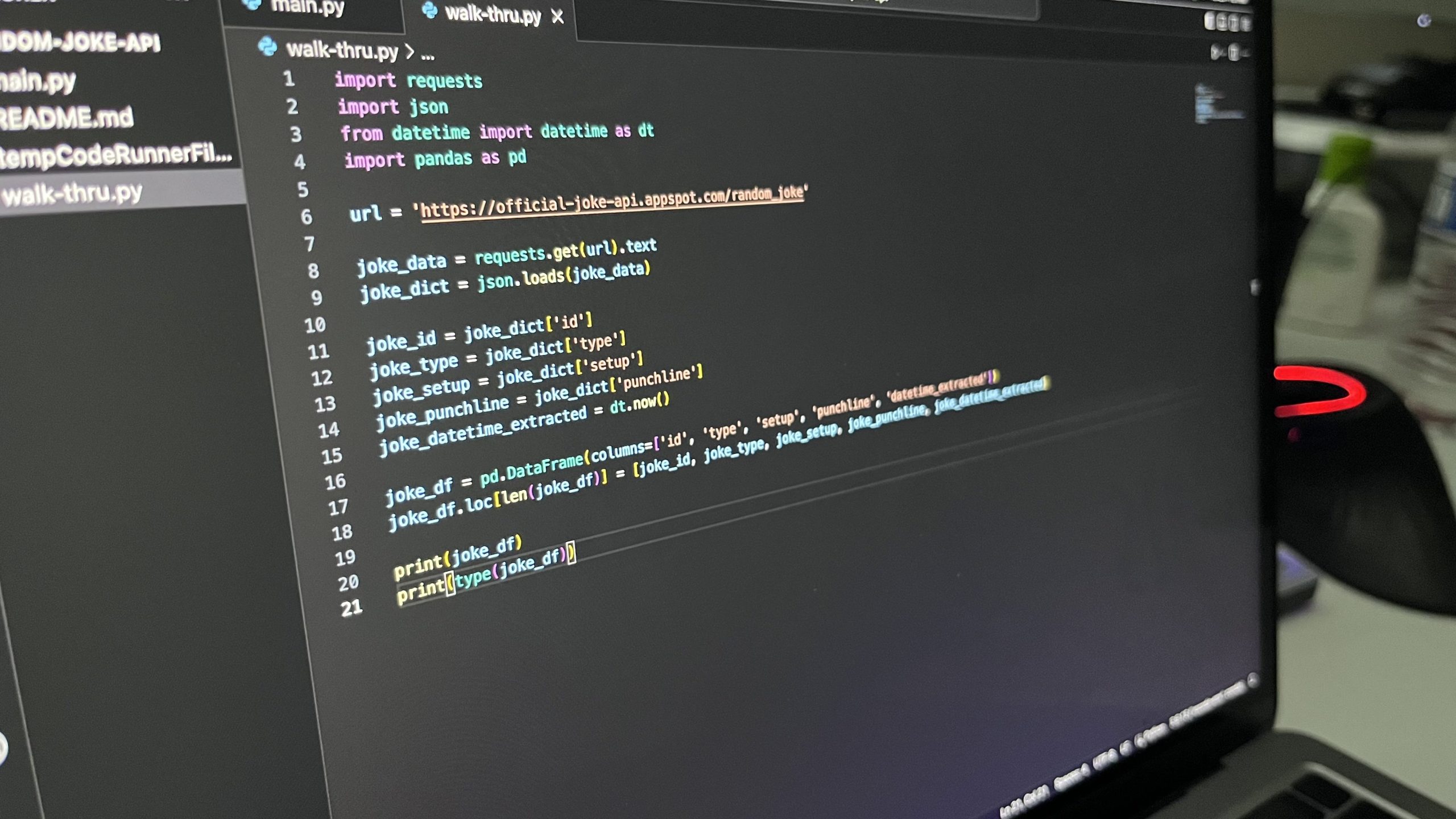
import pandas as pd
joke_df = pd.DataFrame(columns=['id', 'type', 'setup', 'punchline', 'datetime_extracted'])At this point, here is what we have for the whole main.py file: (Putting all our imports at the top of the file…)
I also like to add print(type(variable)) and print(variable) at the end to validate I’m getting the correct output I want…
import requests
import json
from datetime import datetime as dt
import pandas as pd
url = 'https://official-joke-api.appspot.com/random_joke'
joke_data = requests.get(url).text
joke_dict = json.loads(joke_data)
joke_id = joke_dict['id']
joke_type = joke_dict['type']
joke_setup = joke_dict['setup']
joke_punchline = joke_dict['punchline']
joke_datetime_extracted = dt.now()
joke_df = pd.DataFrame(columns=['id', 'type', 'setup', 'punchline', 'datetime_extracted'])
print(joke_df)
print(type(joke_df))Empty DataFrame
Columns: [id, type, setup, punchline, datetime_extracted]
Index: []
<class 'pandas.core.frame.DataFrame'>So far, so good…
Now to add the data into a row in the DataFrame…
Adding a List of Values into a DataFrame as a Row
Use df.loc[len(df)] = [var1, var2, var3]
joke_df.loc[len(joke_df)] = [joke_id, joke_type, joke_setup, joke_punchline, joke_datetime_extracted]All in all, here is what our entire code looks like:
import requests
import json
from datetime import datetime as dt
import pandas as pd
url = 'https://official-joke-api.appspot.com/random_joke'
joke_data = requests.get(url).text
joke_dict = json.loads(joke_data)
joke_id = joke_dict['id']
joke_type = joke_dict['type']
joke_setup = joke_dict['setup']
joke_punchline = joke_dict['punchline']
joke_datetime_extracted = dt.now()
joke_df = pd.DataFrame(columns=['id', 'type', 'setup', 'punchline', 'datetime_extracted'])
joke_df.loc[len(joke_df)] = [joke_id, joke_type, joke_setup, joke_punchline, joke_datetime_extracted]
print(joke_df)
print(type(joke_df))
Yay!
Now we can go on to authenticating with BigQuery, loading, and deploying… in Part 2…